


by Elio Quinton, Centre for Digital Music, Queen Mary University of London
Research in the field of Music Information Retrieval (MIR) aims at developing methods and computational tools to automatically analyse the musical attributes of an audio recording. It could typically consist in extracting chords, tempo or the structural segmentation (e.g. verse, chorus, bridge etc.) of a piece. These tools can then be deployed at a scale that would not be achievable by human beings: it takes a human at the very least the duration of a piece to be able to listen to it in its entirety and analyse it whereas computer systems are fast enough to analyse dozens of tracks in the same time frame. As a result, enormous music collections can be analysed in just a couple of days or weeks.
The recorded music industry is currently going through a period of deep changes in its organisation and business models. Digital music providers, whether it is streaming or download, are no longer just providers of audio content, but strive to deliver a compelling experience centred on music to their customers. In order to achieve this goal, Digital music providers have deployed MIR-powered musical analysis on their music collections, typically totalling dozens of millions of tracks, as they regard musicological metadata as a useful asset. Say for instance that a given user tends to have a preference for songs in a minor key; a discovery playlist themed around songs in minor keys could then be tailored specifically for this user.
However, it is clear that such a system can only be successful if the musicological metadata (i.e. the chords, tempo, segmentation etc.) is correct: building a consumer facing system based on erroneous MIR data is doomed to failure. Despite very good performance, the current state of the art algorithm do not exhibit 100% success rate, which means that they will inevitable produce erroneous outputs. Given the subjective and ambiguous nature of music it is even very unlikely that achieving a 100% accuracy would ever be possible. Nevertheless, it does not mean that MIR-powered musical analysis is doomed to be unusable because of its (partial) unreliability. As with any automated system, inconsistency is a real handicap, but a certain degree of inaccuracy can be dealt with, provided that it features some form of consistency and that there exist means of assessing the inaccuracy. MIR feature extraction systems do not always provide a confidence value alongside with the musical estimate, so that one has to blindly rely on the output produced, knowing that this assumption will be wrong in some instances.
In this work we propose a method to predict the reliability of MIR feature extraction independently of the extraction itself, so that potential failures can be handled. As a result MIR-powered musical analysis is made safely usable in larger systems. For instance, let us consider a hypothetical consumer-facing scenario in which a mobile app requires a tempo estimate to deliver a compelling experience to the user. Having a reliability value attached to tempo estimates enables the app to chose whether to use this data or not. Only tempi with high reliability value may be used to generate behaviours presented to the user (Fig.1).
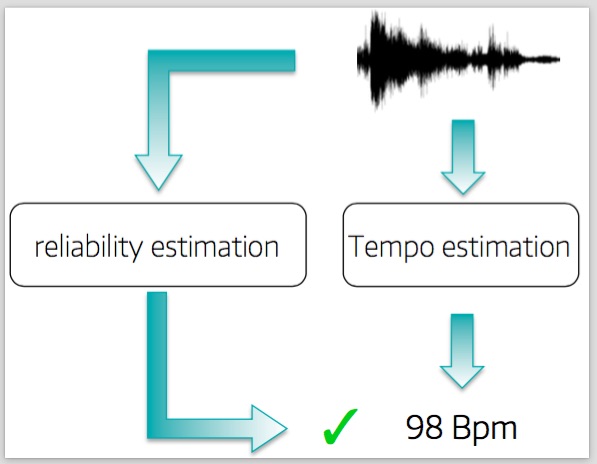
Fig.1 Prediction of the reliability of feature extraction
Now, how does such a prediction system work? The body of research MIR carried out since its infancy has allowed researchers to identify properties of the music signal that are challenging for MIR algorithms. In other words, when a track exhibit such properties, it is very likely that the feature estimation will fail. Our method consists in measuring these attributes and using them to produce a reliability estimate. Let us illustrate this process with an analogy with road driving. Let’s assume the task is to drive a car as fast as possible without crashing. The experience of drivers, car manufacturers and more generally the laws of physics clearly suggest that a much higher top speed is reachable on a modern motorway than on a muddy track in the woods (Fig. 2). Therefore, an estimate of the maximum top speed achievable can be produced by observing the track/road on which a car is to be driven, without the need for a test drive.

Fig. 2 Check the track: analogy with road type vs. top speed
In short, our method assess whether the music recording under analysis looks more like a motorway (high reliability), a narrow muddy track (low reliability), or anything in between. This information is then used to produce a reliability estimate for the corresponding MIR feature (e.g. tempo).
Find out more about the technical details in our publication:
E.Quinton, M.Sandler, and S.Dixon, “Estimation of the Reliability of Multiple Rhythm Features Extraction from a Single Descriptor.” IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2016.