


Using a computer to detect which notes have been played in an audio recording of a piece of music is commonly referred to as automatic music transcription. In the context of understanding the music behind a recording, transcription techniques have often been called a key technology as concepts such as chords, harmony and rhythm are musically defined based on notes. Given the importance of this foundational technology, researchers have started working on automatic music transcription since computers became more widely available, with early approaches dating back to the 1970s. However, despite considerable interest during the next decades, the general transcription problem withstood all attempts to find a final solution to its challenges, holding back many interesting applications.
Given its musical importance, transcription has been a central component in the FAST project from the start. A major aim of the FAST project is to explore how signal processing and machine learning methods, which includes approaches for music transcription, can not only incrementally but substantially be improved by exploiting knowledge of the music production process. In this context, the FAST team has analyzed, when and why current transcription methods typically fail, from a musical, acoustical, statistical and numerical point of view, and how structured information about the recording process could be useful in this context.
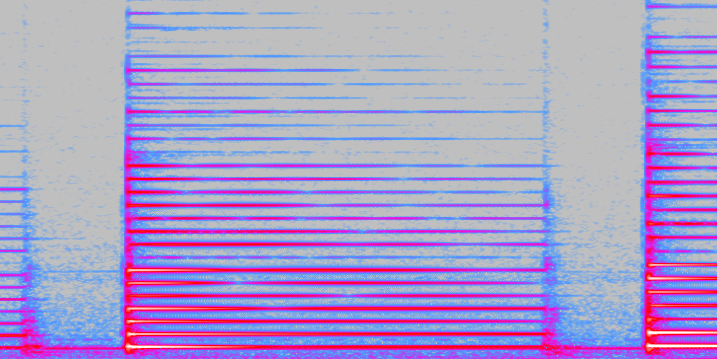
Figure 1. Time-frequency representation of a single note played on a piano
Figure 1 illustrates one such problem. Here, we can see a so called time-frequency representation of a single note played on a piano, which is a representation typically used to describe when a frequency is active in the recording and how strong it is. Here, we can see several lines or harmonics, which represent the strongest frequency components of the note and all together specify how the note sounds. However, although this is a single note, we can see that some harmonics decay more quickly than others, some vanish in between and reappear a little bit later, and at the beginning of the note almost all frequencies are more or less active. If the intensity of frequencies changes over time like this, a sound is often called non-stationary. This inner-note non-stationarity has usually not been considered in automatic music transcription because it would require a high level of detail in a computational model of the sound. For mathematical reasons, this level of detail would usually make a robust estimation of the most important parameters extremely difficult – figuratively speaking, with that much detail, it becomes difficult for an algorithm to see the wood for the trees.
After identifying such issues, we proposed and implemented a novel sound model that can take this level of detail into account to better identify which notes are active in a given recording. The foundation here was that in controlled recording conditions, we know, first, which type of instrument is playing and second, that we can obtain examples of single notes for that instrument. This way, we could focus on a specific instrument class (pitched percussive instruments such as the piano), which enabled us to increase the level of detail such that it not only became possible to model the interaction of the notes but additionally how we expect the notes to change over time. The result was a first sound model for music transcription that was capable of modelling highly non-stationary note sound-objects of variable length.
With this level of detail, a sound model contains many parameters, which we need to set correctly for the model to work as expected. From a mathematical point of view, this is quite difficult – i.e. it was not clear how we can find correct values for the parameters in our model. However, we developed a new parameter estimation method based on a mathematical framework called Alternating Directions Method of Multiplier (ADMM). This framework provides a lot of flexibility and enabled us to design various so called regularizers, which stabilize the parameter estimation process and make sure that we find meaningful values.
Overall, with the new sound model and parameter estimation methods for high detail sound modelling in place, we found our results to exceed the current state-of-the-art by far, by reducing error rates on often used, real acoustical recordings considerably, with previous error rates often being several times higher than ours. This considerable improvement demonstrates that additional information available from the production process can be translated into more detailed models while still being able to robustly find the parameters needed. The new method will enable a variety of new developments within the FAST project in the future.
Our method will be published soon in the IEEE/ACM Transcriptions on Audio, Speech and Language Processing: https://bit.ly/2asgHDf