


by Brecht De Man, C4DM, Queen Mary University of London
Many types of audio research rely on multitrack recorded or otherwise generated audio (and sometimes mixes thereof) for analysis or for demonstration of algorithms. In this context, a ‘mix’ denotes a summation of processed versions of (a subset of) these tracks, that can itself be processed as well. The availability of this type of data is of vital importance to many researchers, but also useful for budding mix engineers looking for practice material, audio educators, developers, as well as musicians or creative professionals in need of accompanying music or other audio where some tracks can be disabled.
Among the types of research that require or could benefit from a large number of audio tracks, mixes and/or processing parameters, are analysis of production practices, source separation, automatic mixing, automatic multitrack segmentation, applications of masking and other auditory phenomena, and others that we haven’t thought of yet.
Existing online resources of multitrack audio content have a relatively low number of songs, show little variation in content, contain content of which the use is restricted due to copyright, provide little to no metadata, rarely have mixed versions including the parameter settings, and/or do not come with facilities to search the content for specific criteria.
For a multitrack audio resource to be useful for the wider research community, it should be highly diverse in terms of genre, instrumentation, and quality, so that sufficient data is available for most applications. Where training on large datasets is needed, such as with machine learning applications, a large number of audio samples is especially critical. Data that can be shared without limits, on account of a Creative Commons or similar license, facilitates collaboration, reproducibility and demonstration of research and even allows it to be used in commercial settings, making the testbed appealing to a larger audience. Moreover, reliable metadata can serve as a ground truth that is necessary for applications such as instrument identification, where the algorithm’s output needs to be compared to the ‘actual’ instrument. Providing this data makes the testbed an attractive resource for training or testing such algorithms as it obviates the need for manual annotation of the audio, which can be particularly tedious if the number of files becomes large. Similarly, for the testbed to be highly usable it is mandatory that the desired type of data can be easily retrieved by filtering or searches pertaining to this metadata.
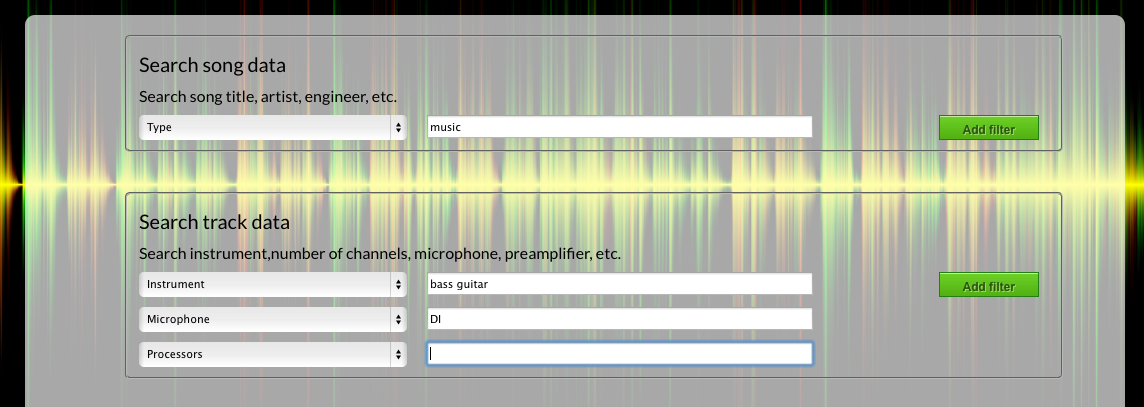
For this reason, we present a testbed that
- can host a large amount of data;
- supports a variety of data of varying type and quality, including raw tracks, stems, mixes (plural), and digital audio workstation (DAW) files;
- contains data under Creative Commons license or similar (including those allowing commercial use);
- offers the possibility to add a wide range of meaningful metadata;
- comes with a semantic database to easily browse, filter and search based on all metadata fields.
The testbed can be accessed here.