by Sean McGrath, Mixed Reality Lab, Nottingham University
Recent work at the Mixed Reality Lab, Nottingham University has begun to explore and unpack the work of music producers and performers with a focus on their attitudes, working practices and use of tools and technology. We explore a complex set of interactions between people and technology in order to facilitate the production and dissemination of audio content in an evolving digital climate. The work extends from early production through to mixing, mastering, distribution and consumption. We explore how individuals in this space curate and collect content, with a view to reuse in the future, their roles, agendas and goals and the use of technology within this space.

Image 1. The definition of a studio environment changes as bedroom producers now have access to a range of tools
We also explore emerging technology, how technology is affecting practice and ways in which technology might be able to facilitate the work that people do in the future. Finally, we explore technological issues that pertain to music production and dissemination in its current state and implications for design for future applications and contexts. Some of the contexts that our work focuses on include:
- Amateur producers
- Pro-Amateur producers
- Professional “at work” producers
- Communities of artists (grime, hip-hop)
- Mobile modular music making
- The studio space, what this means and how its meaning is quickly changing
- Distributed music production
- The role of social media in music making
Much of our work has been about untangling the complexities of music production in a shifting sociotechnical environment. Metadata has emerged as a particularly interesting feature of the engagements with artists and communities of artists. This metadata pertains to the types of things that people might want to know about how a track is composed. This type of metadata ranges from the mundane (bpm, pitch, key) to more contextually rich information about how a track was recorded, locative data and the arrangement of technology within a space. Though many DAWs embed metadata in a number of ways, grouping according to associated themes, in particular spaces or colour coding, there is much work to be done in this space. We must take what we have learned from these engagements about how people work and what people do and try to apply these lessons in future production technologies.
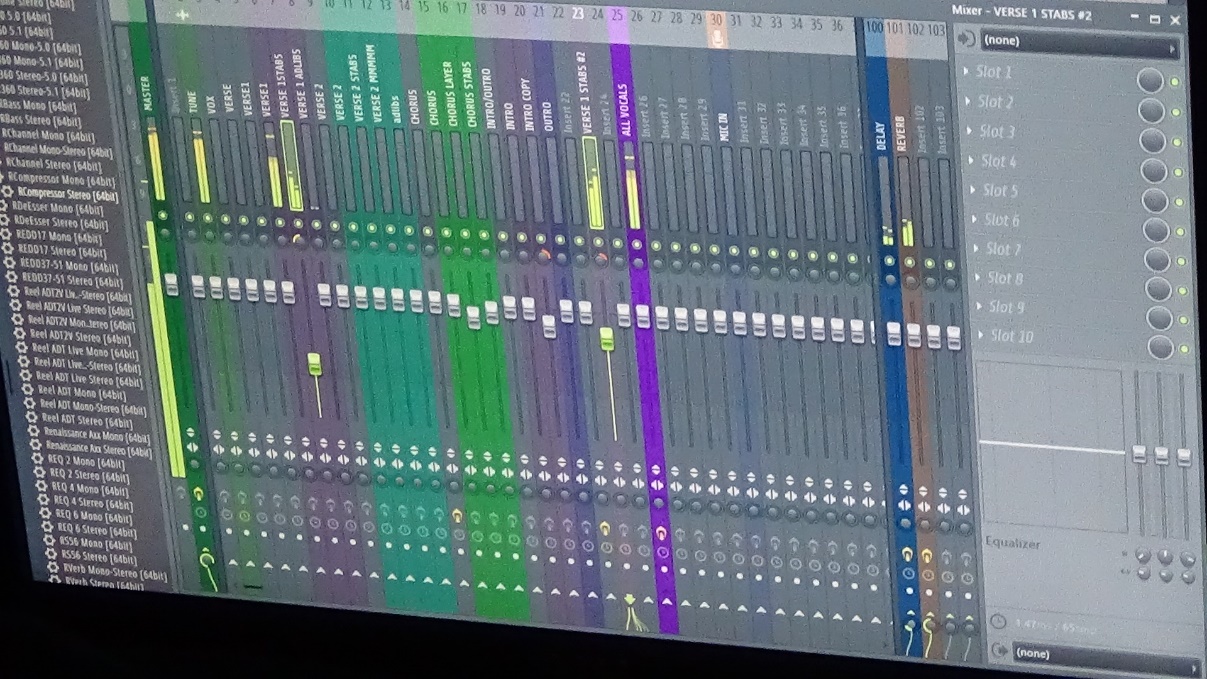
Image 2. A digital audio workstation containing a range of contextually relevant metadata
Our work focuses on a community of artists with varying levels of technical and technological skill. We explore their roles, working patterns, behaviours and apply the particular lens of social media to investigate their activities and intentions within this space. This work will be presented at the 2nd AES Workshop on Intelligent Music Production on 13 Sep 2016 as a poster. We will also be presenting both a long paper on production practice and a poster on the social media aspect of the work at Audio Mostly 2016 on October the 6th in Sweden.